阅读收益
- 掌握n8n私有化部署的完整流程
- 学习RSS到钉钉的消息流转实现
- 深入理解n8n的Python扩展开发
- 获取即用型钉钉推送工作流模板
- 掌握自动化工作流的调试技巧
- 需要搭建自动化RSS信息聚合的团队
- 想要实现钉钉群自动化推送的开发者
- 对工作流自动化感兴趣的运维工程师
- 寻找开源自动化工具的技术爱好者
在开始安装n8n之前,我们需要创建必要的目录结构。以下命令会在用户主目录下创建所需的文件夹:
# 切换到root用户
su
# 输入密码
# 创建n8n主目录及其子目录
mkdir -p /root/data/docker_data/n8n/
# 命令解析:
# mkdir: 创建目录的命令
# -p: 如果父目录不存在则创建
# /root/data/docker_data/n8n/: 在/root/data/docker_data/目录下创建n8n文件夹
# 进入n8n目录
cd /root/data/docker_data/n8n/
在这一步,我们将配置Docker Compose来管理n8n及其依赖服务。这种方式相比直接运行容器更易于管理和维护。
创建docker-compose.yml文件:
cd /root/data/docker_data/n8n/
vim docker-compose.yml
version: "3.8"
volumes:
db_storage:
n8n_storage:
services:
n8n-postgres:
image: postgres:16
container_name: n8n-postgres
restart: always
environment:
- POSTGRES_USER
- POSTGRES_PASSWORD
- POSTGRES_DB
- POSTGRES_NON_ROOT_USER
- POSTGRES_NON_ROOT_PASSWORD
volumes:
- db_storage:/var/lib/postgresql/data
- ./init-data.sh:/docker-entrypoint-initdb.d/init-data.sh
healthcheck:
test: ['CMD-SHELL', 'pg_isready -h localhost -U ${POSTGRES_USER} -d ${POSTGRES_DB}']
interval: 5s
timeout: 5s
retries: 10
n8n:
build:
context: .
dockerfile: Dockerfile
image: n8n-custom
container_name: n8n
restart: always
environment:
- N8N_HOST=${N8N_HOST}
- NODE_ENV=production
- N8N_EDITOR_BASE_URL=${N8N_EDITOR_BASE_URL}
- VUE_APP_URL_BASE_API=${N8N_EDITOR_BASE_URL}
- WEBHOOK_URL=${N8N_EDITOR_BASE_URL}
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=n8n-postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=${POSTGRES_DB}
- DB_POSTGRESDB_USER=${POSTGRES_NON_ROOT_USER}
- DB_POSTGRESDB_PASSWORD=${POSTGRES_NON_ROOT_PASSWORD}
- TZ=Asia/Shanghai
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=false
- NODE_FUNCTION_ALLOW_BUILTIN=*
- NODE_TLS_REJECT_UNAUTHORIZED=0
ports:
- 5678:5678
links:
- n8n-postgres
volumes:
- n8n_storage:/home/node/.n8n
depends_on:
n8n-postgres:
condition: service_healthy
为了扩展n8n的功能,我们需要添加Python环境和相关依赖。这使得n8n能够处理更复杂的数据转换任务。
cd /root/data/docker_data/n8n/
vim Dockerfile
创建Dockerfile文件,添加自定义Python库支持:
FROM docker.n8n.io/n8nio/n8n:latest
USER root
# 安装Python环境
RUN apk add --no-cache python3 py3-pip
# 创建虚拟环境
RUN python3 -m venv /opt/venv
# 激活虚拟环境并安装依赖
ENV PATH="/opt/venv/bin:$PATH"
RUN pip install --no-cache-dir html2text beautifulsoup4
# 切换回node用户
USER node
cd /root/data/docker_data/n8n/
vim .env
创建.env文件,添加以下内容:
N8N_HOST=你的服务器IP
N8N_EDITOR_BASE_URL=http://你的服务器IP:5678
POSTGRES_USER=admin
POSTGRES_PASSWORD=123456
POSTGRES_DB=n8n
POSTGRES_NON_ROOT_USER=admin
POSTGRES_NON_ROOT_PASSWORD=123456
执行以下命令启动n8n,如果没有安装Docker,请先安装Docker:
docker compose up -d
访问http://your-ip:5678完成账号密码初始化设置。
在开始配置工作流之前,需要先完成钉钉机器人的接入配置。这一步对于后续的消息推送至关重要。
- 在钉钉群中-设置-机器人-添加机器人-自定义机器人
- 安全设置选择"加签"
- 保存access_token和secret
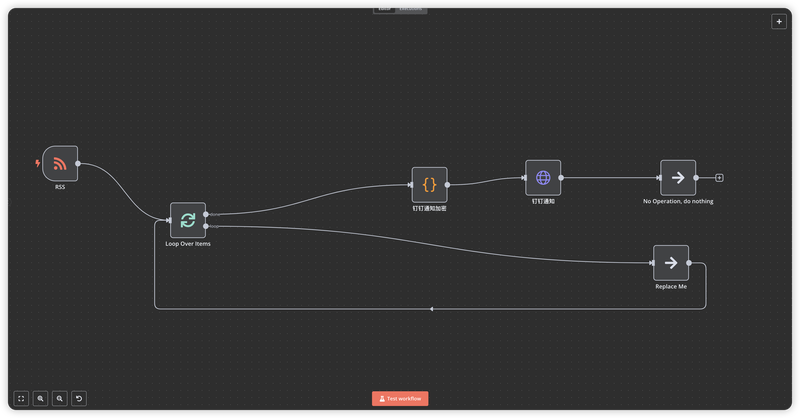
工作流是n8n的核心概念,通过可视化的方式连接各个功能节点,实现数据的流转和处理。
新建一个工作流,右侧搜索选择节点:
- RSS Trigger
- Code
- HTTP Request
工作流包含以下节点:
| 节点类型 | 作用 | 配置要点 |
|---|
| RSS Trigger | 定时获取RSS更新 | 设置轮询间隔 |
| Code | 生成钉钉签名 | 使用HMAC-SHA256算法 |
| HTTP Request | 发送钉钉消息 | 配置Webhook URL |
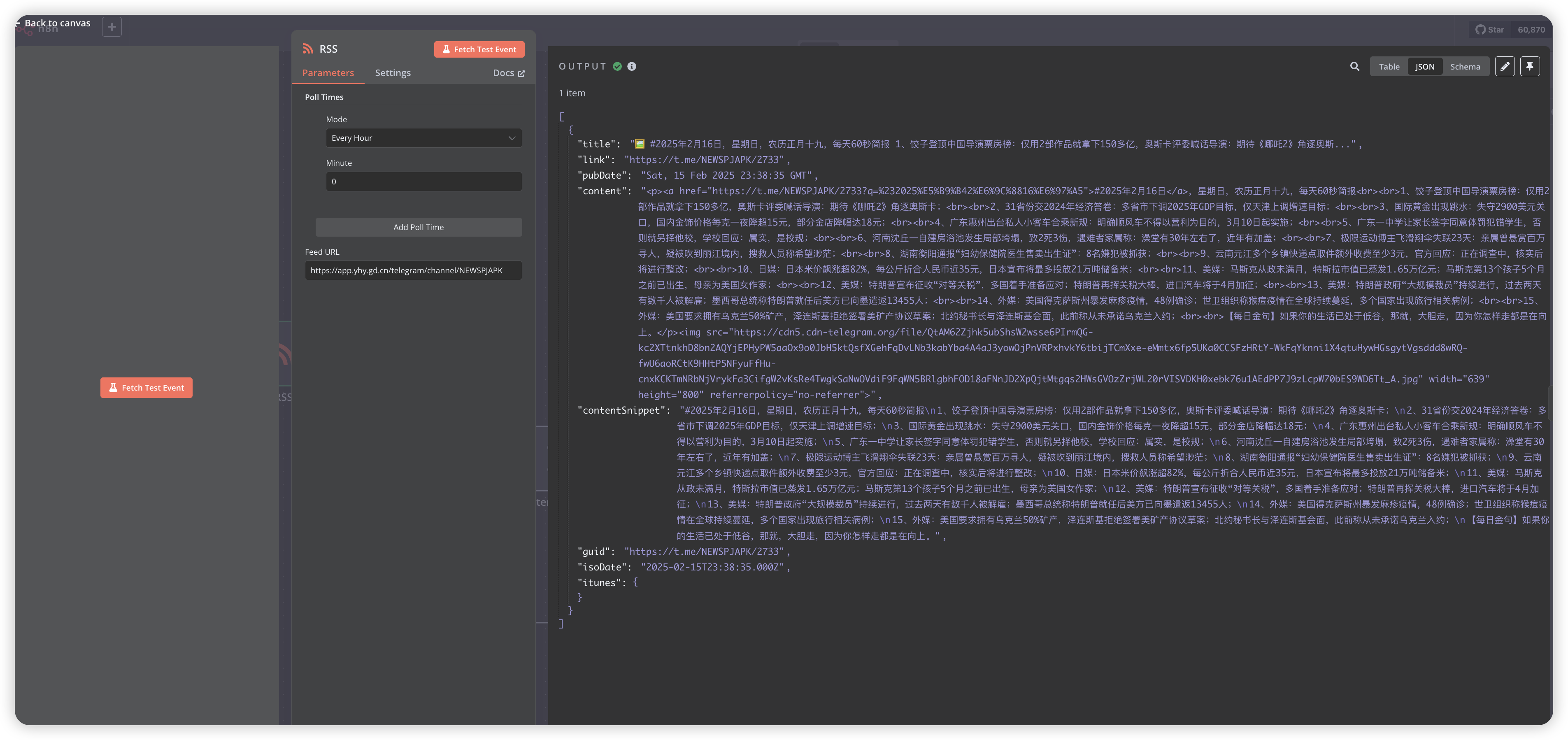
- 选择RSS Trigger节点
- 配置轮询间隔,这里设置为1小时
- 选择RSS源,这里以Telegram频道的每天新闻为例
https://app.yhy.gd.cn/telegram/channel/NEWSPJAPK
- 点击
Fetch Test Event,测试节点返回数据
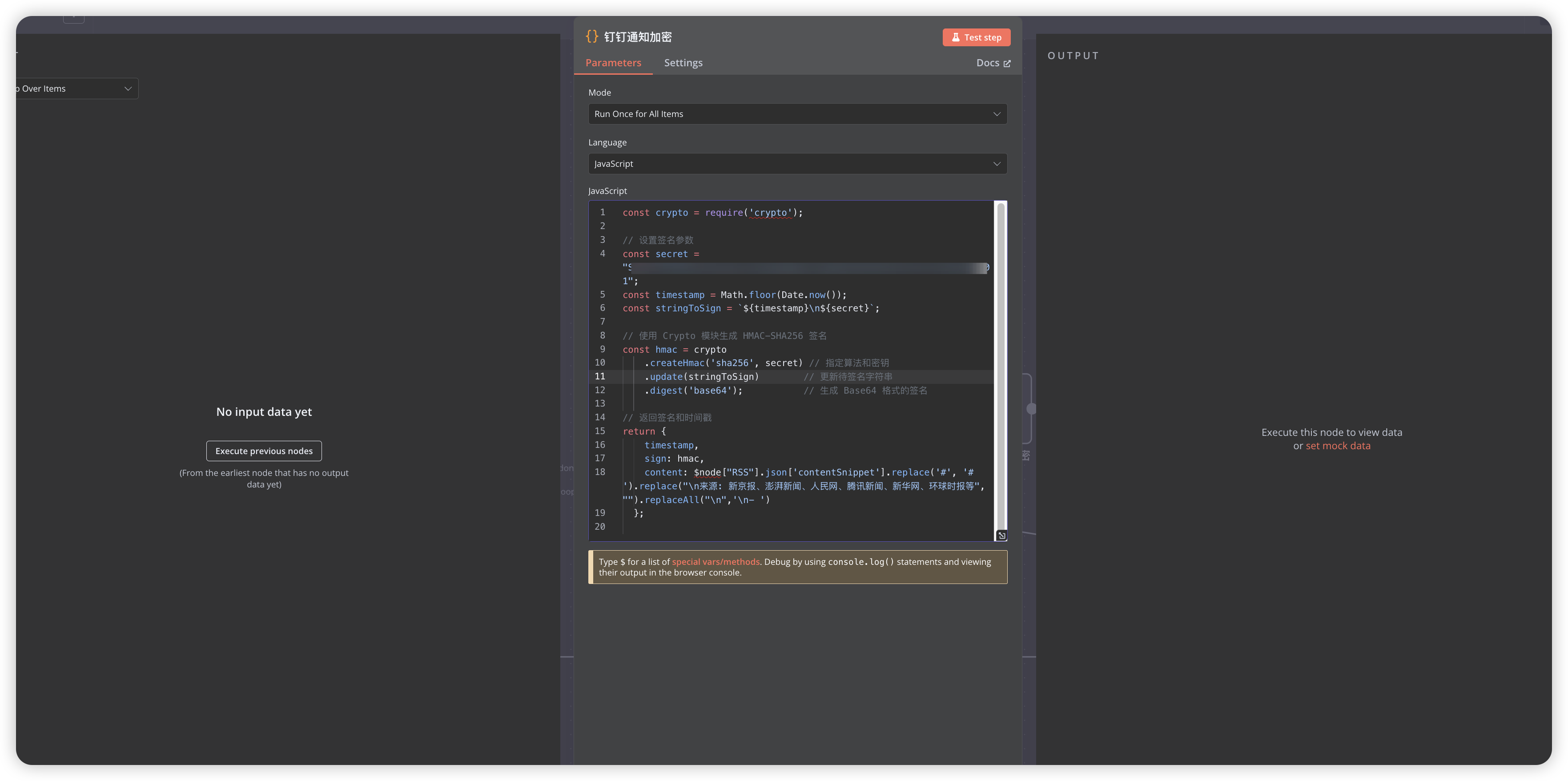
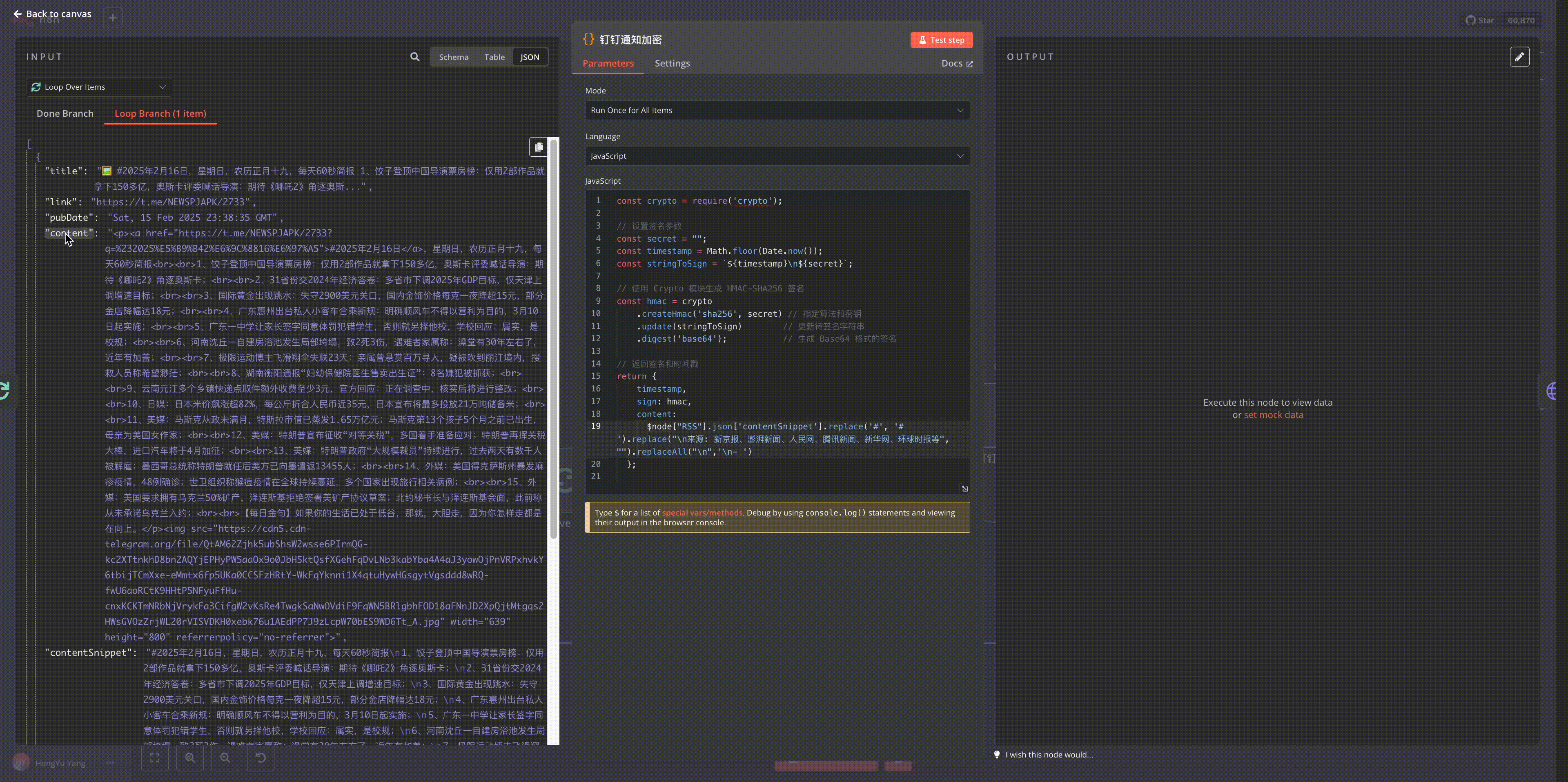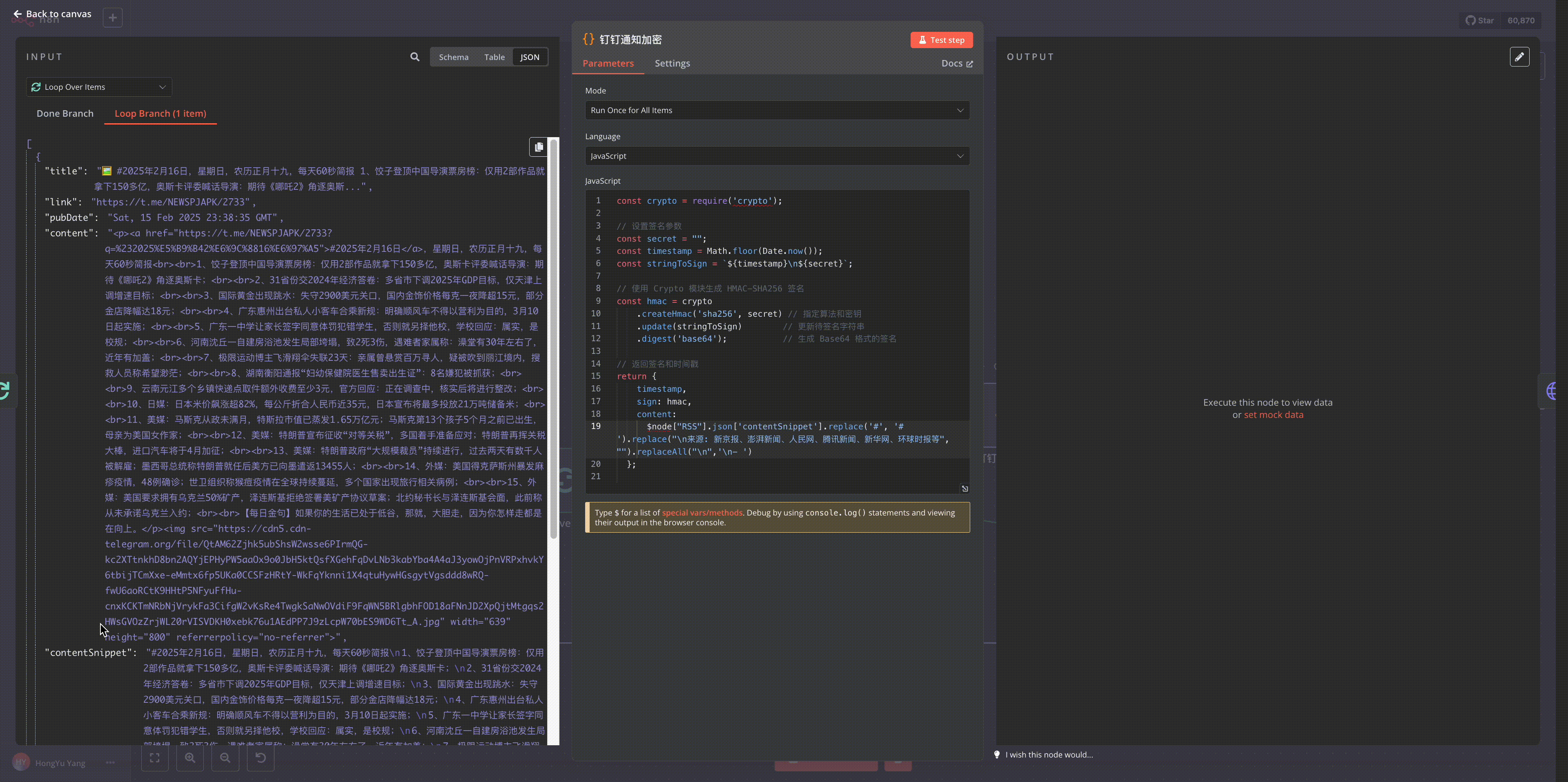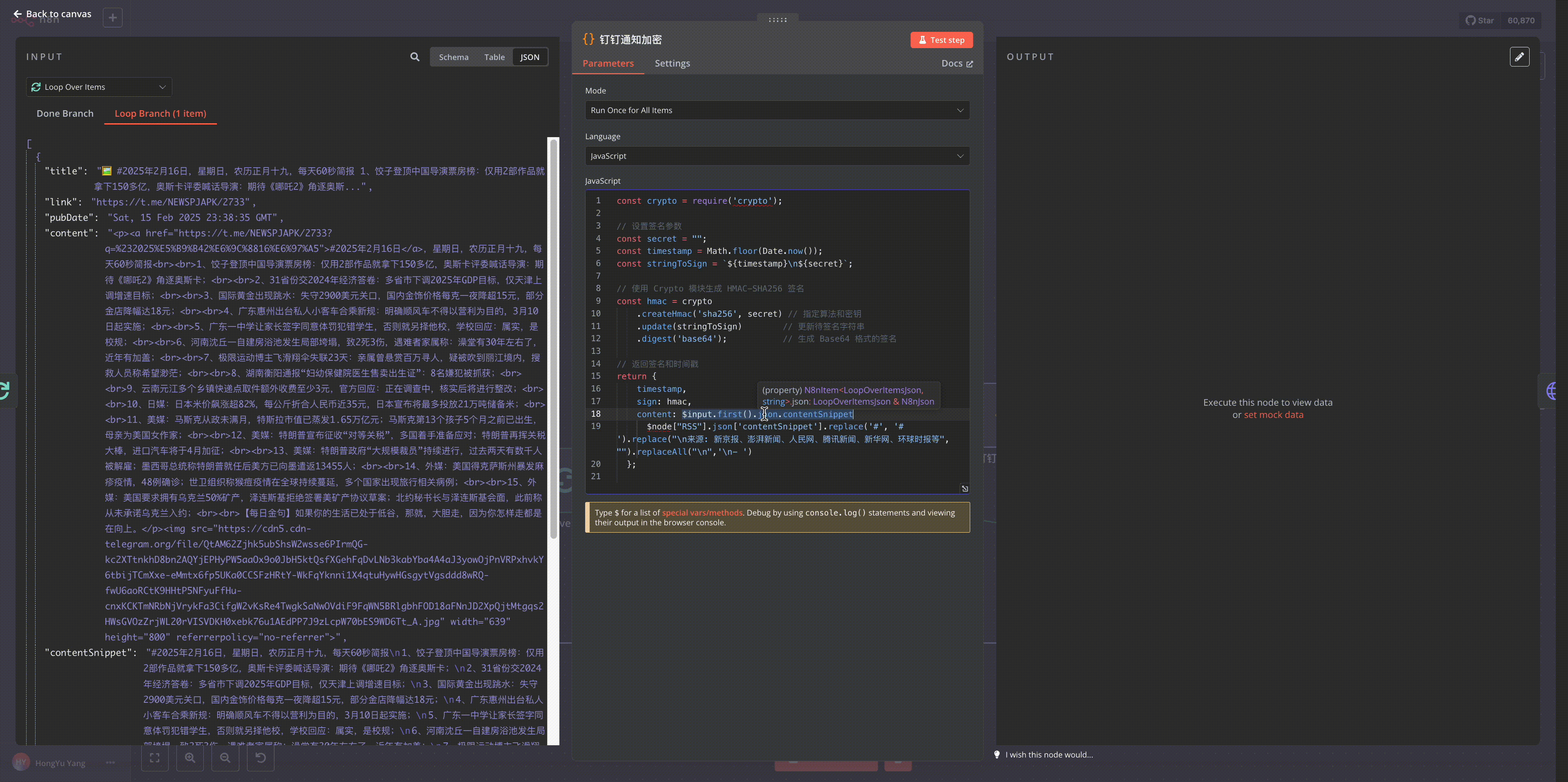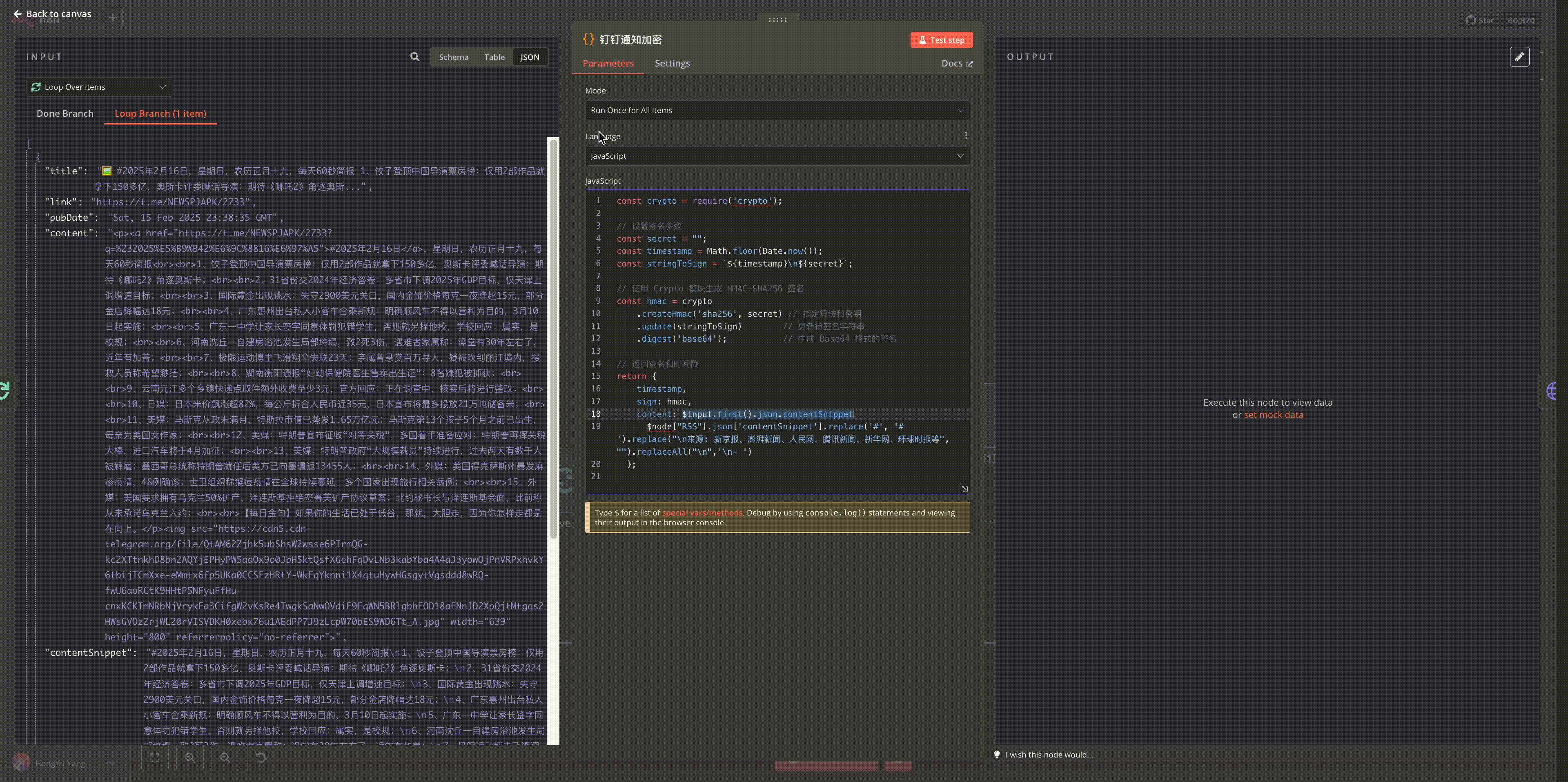
钉钉签名生成代码:
// 设置签名参数
const secret = "your_secret";
const timestamp = Math.floor(Date.now());
const stringToSign = `${timestamp}\n${secret}`;
// 使用 Crypto 模块生成 HMAC-SHA256 签名
const hmac = crypto
.createHmac('sha256', secret) // 指定算法和密钥
.update(stringToSign) // 更新待签名字符串
.digest('base64'); // 生成 Base64 格式的签名
// 返回签名和时间戳
return {
timestamp,
sign: hmac,
content: $node["RSS"].json['contentSnippet'].replace('#', '# ').replace("\n来源: 新京报、澎湃新闻、人民网、腾讯新闻、新华网、环球时报等", "").replaceAll("\n",'\n- ')
};
- 选择Post请求
- 配置Webhook URL,右上角选择Expression,会把{{}}里的内容替换为实际值,node里面的名字就是前面的节点名称,比如原始的名称应该是RSS和Code
https://oapi.dingtalk.com/robot/send?access_token=your_access_token×tamp={{$node["钉钉通知加密"].json["timestamp"]}}&sign={{$node["钉钉通知加密"].json["sign"]}}
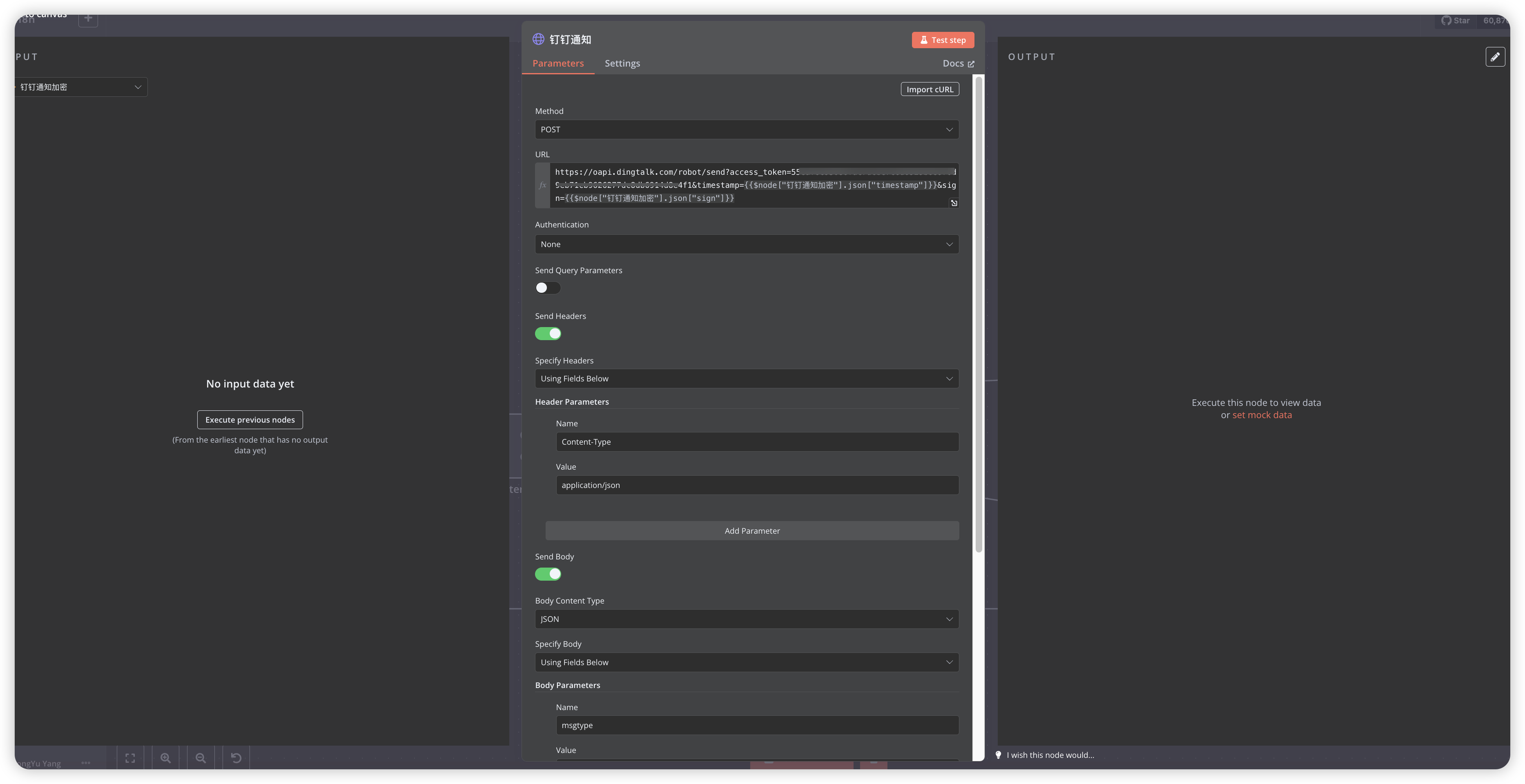
- 配置请求头
Content-Type: application/json
- 配置请求体,除了markdown里的内容是表达式,其他都是固定值
{
"msgtype": "text",
"text": {
"content": "{{$node["HTML转Markdown"].json["content"]}}"
}
}
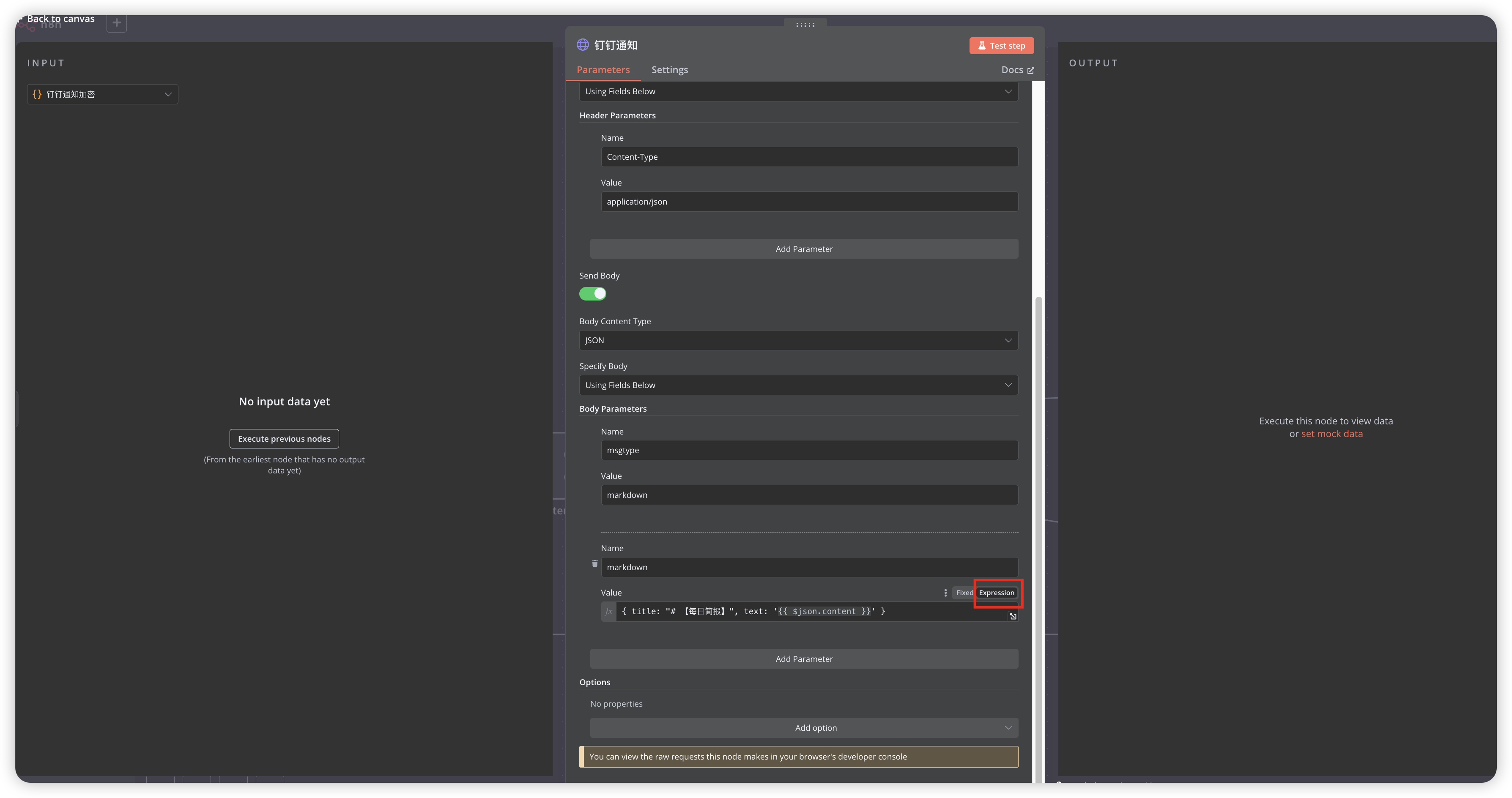
配置完成后就可以点击测试工作流了

对于变量值不知道怎么写,可以在n8n中运行之前的节点后进行拖拽值到对应的位置就行
n8n的强大之处在于其扩展性,我们可以通过Python脚本增强其数据处理能力。
- 选择Code节点,先对RSS返回的内容进行转义处理
// Code 节点内容
const htmlContent = $input.first().json.content
// 对内容进行转义处理
const escapedContent = JSON.stringify(htmlContent)
.replace(/'/g, "\\'") // 转义单引号
.slice(1, -1); // 移除 JSON.stringify 添加的首尾双引号
// 返回转义后的内容
return {
json: {
escaped_content: escapedContent
}
};
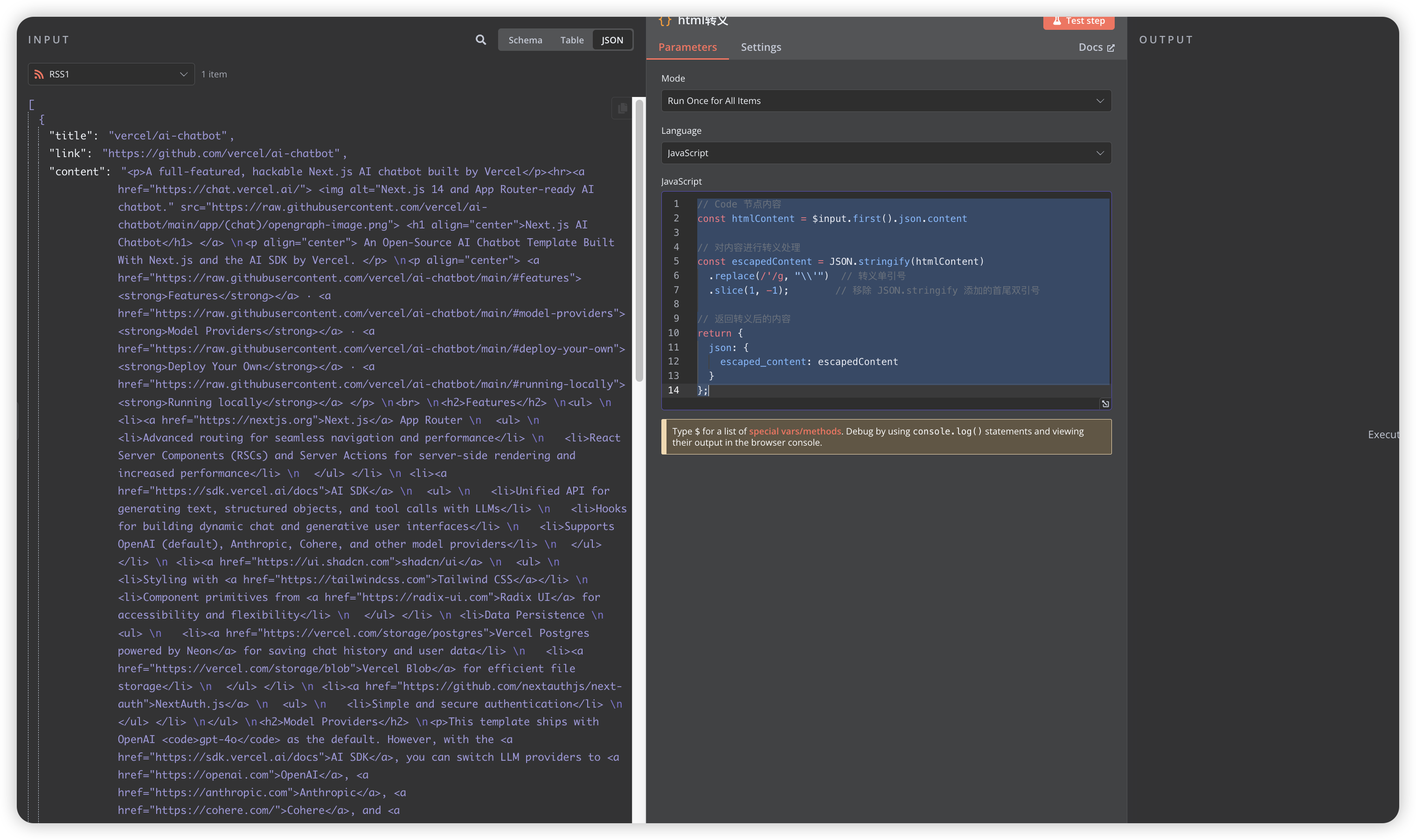
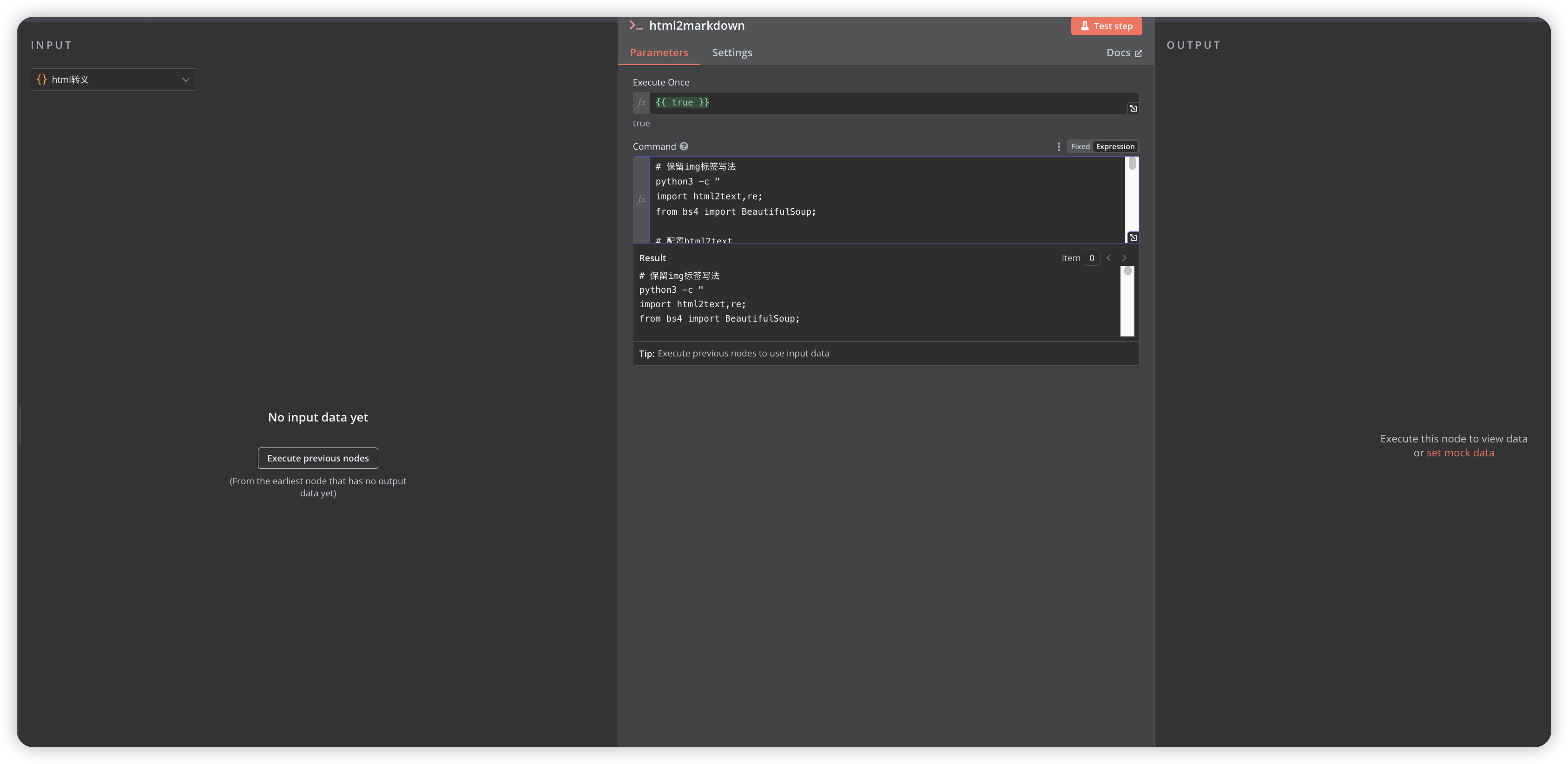
- 使用
Excute Command节点,调用服务器安装的Python库进行HTML转Markdown处理
- 使用Python处理HTML内容, 图片转成markdown后,尺寸无法修改,这里对图片进行处理,保留原始的img标签写法,然后进行markdown转换(钉钉通知好像img标签无法显示,后续在进行其他办法优化):
- 前面转义后,这里需要进行解码处理(代码可后续重新优化)
python3 -c "
import html2text,re;
from bs4 import BeautifulSoup;
# 配置html2text
h=html2text.HTML2Text();
h.ignore_links=False;
h.body_width=0;
h.escape_snob=True;
h.unicode_snob=True;
h.mark_code=False;
# 预处理HTML内容
content='{{ $json.escaped_content }}'.replace('\\\\\"','\\'').replace('\\\"','\"');
# 使用BeautifulSoup提取和保留原始图片标签
soup=BeautifulSoup(content,'html.parser');
img_tags={};
for img in soup.find_all('img'):
if img.get('style') or img.get('width') or img.get('height'):
img_str = str(img).replace('\"', '\\'');
img_tags[img.get('src','')] = img_str;
# 转换为Markdown
md=h.handle(content);
# 处理所有转义字符
md=md.replace(r'\(',r'(').replace(r'\)',r')').replace(r'\[',r'[').replace(r'\]',r']').replace(r'\.', r'.').replace(r'\-',r'-').replace(r'\n',r'\n').replace(r'\!',r'!').replace('\"', '\\'');
# 将markdown图片语法替换回原始的HTML标签
for src, html_tag in img_tags.items():
pattern=f'!\\[([^\\]]*)\\]\\({re.escape(src)}\\)';
md=re.sub(pattern, html_tag, md);
print(md);"
为了提高工作流的稳定性和效率,我们需要对大量数据进行分批处理。
- 新增Code节点,对返回的数据进行分批次处理,代码分割根据实际情况调整
// Code 节点内容
// split_batch 节点
const htmlContent = $input.first().json.stdout
const products = htmlContent.split('* * *');
const batchSize = 5; // 每批发送5个产品
// 将产品分成多个批次
const batches = products.reduce((acc, product, index) => {
const batchIndex = Math.floor(index / batchSize);
if (!acc[batchIndex]) {
acc[batchIndex] = [];
}
acc[batchIndex].push(product);
return acc;
}, []);
return batches.map(batch => ({
json: {
content: batch.join('\n---\n')
}
}));
- 新增Loop Over Items节点,对分批次后的数据进行循环处理(无需修改配置,直接连接就行)
- Loop连接下一步操作,比如钉钉加签和钉钉通知
- 钉钉通知后面重新连接回Loop Over Items节点,进行下一批次处理
- 可以自行添加循环成功处理连接到Done节点
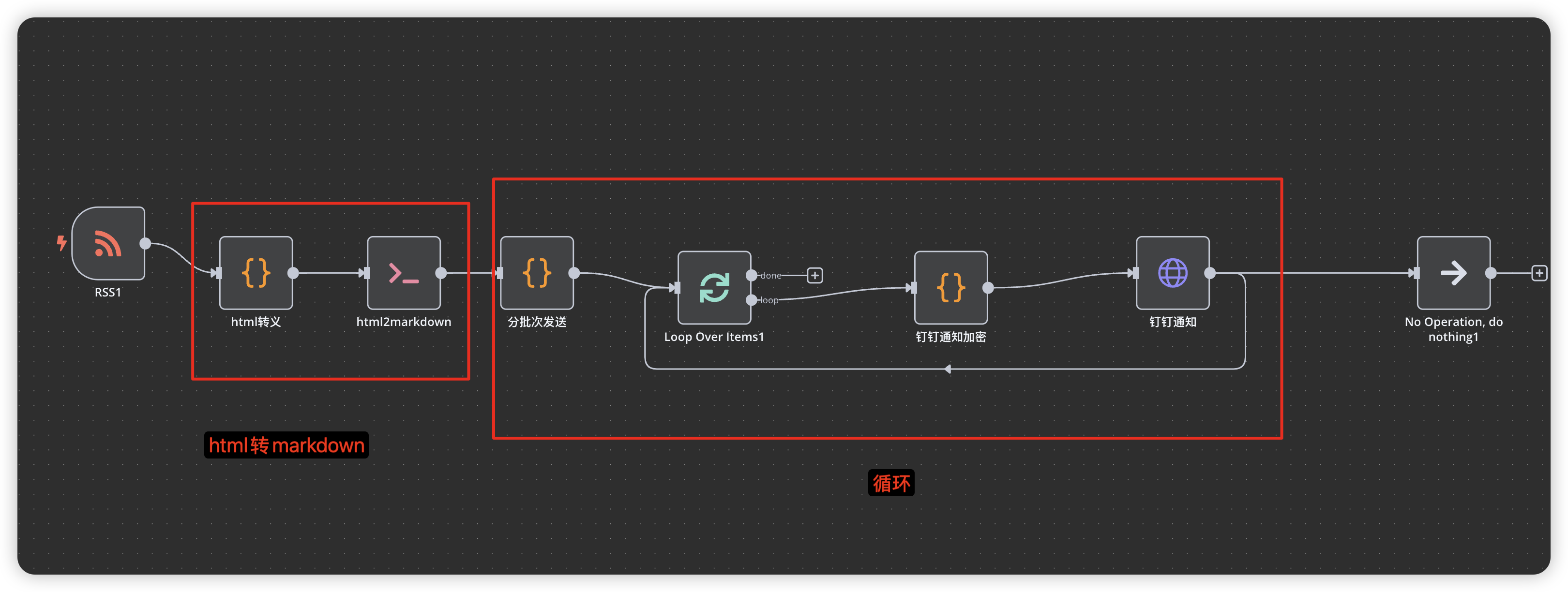
在部署和使用过程中,你可能会遇到以下常见问题:
- Python模块安装失败
- 钉钉签名验证错误
- 时区配置不正确
- Markdown渲染异常
本节将详细介绍这些问题的解决方案。
- Python模块未找到
- 首先,需要在你的n8n中安装好html2text库,这个之前在Dockerfile中已经配置安装进去了,如果需要更多库,可以自行添加安装
- 配置Dockerfile后,需要重新启动n8n服务
docker compose down
docker compose up -d
# 进入docker容器中,检查是否安装成功
docker exec -it n8n /bin/sh
# 切换到 node 用户(n8n 的运行用户)
su node
# 检查 Python 环境路径
which python3
# 尝试导入库
python3 -c "import html2text; print(html2text.__version__)"
- 如果没安装成功,删除n8n容器镜像,重新启动n8n服务测试
# 查看n8n容器镜像
docker image ls
# 删除n8n容器镜像
docker rmi custom-n8n
# 重新启动n8n服务
docker compose up -d
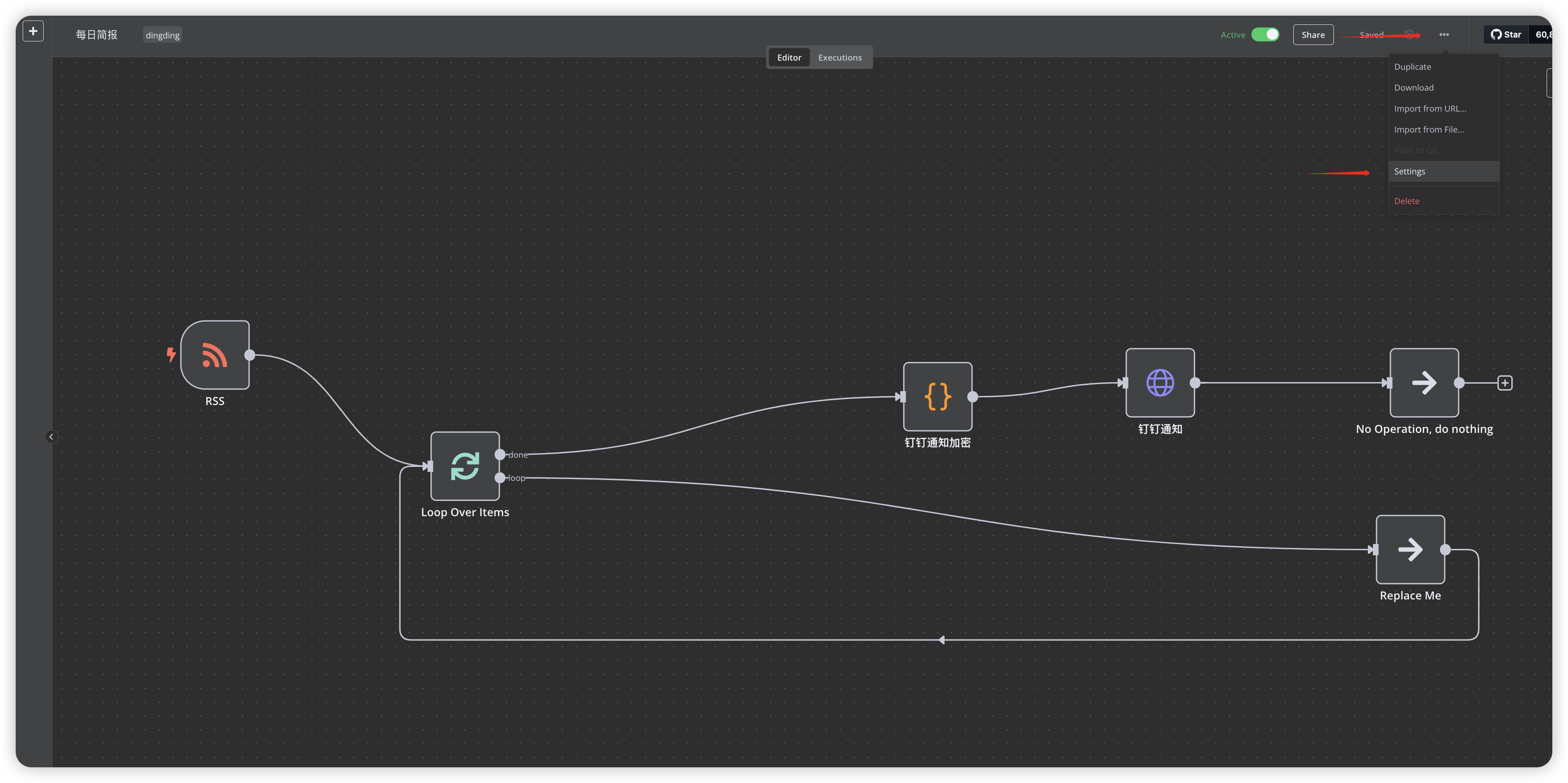
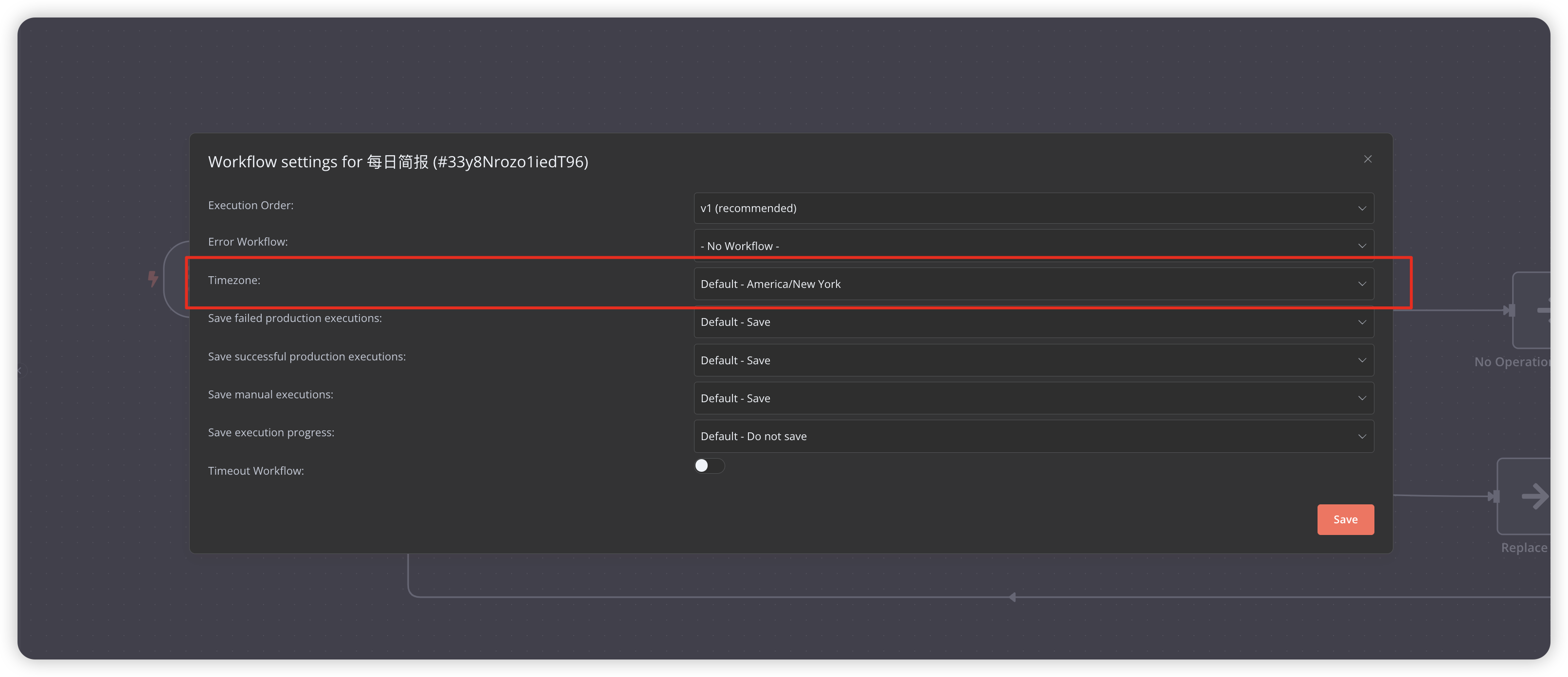
钉钉签名验证失败
- 检查时间戳格式
- 验证secret是否正确
- 检查服务器时间时区是否正确
- 修改工作流时区看看是否有影响 (参考下图)
Markdown渲染异常
3.4 每日新闻钉钉通知工作流
{
"name": "每日简报",
"nodes": [
{
"parameters": {
"options": {
}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [-100, 40],
"id": "493ff425-c792-4e40-99da-129dddaa65e0",
"name": "Loop Over Items"
},
{
"parameters": {
},
"type": "n8n-nodes-base.noOp",
"name": "Replace Me",
"typeVersion": 1,
"position": [1260, 160],
"id": "d54910a6-a2d6-43b7-9677-e388a6f8e41e"
},
{
"parameters": {
"method": "POST",
"url": "=https://oapi.dingtalk.com/robot/send?access_token=your_access_token×tamp={{$node[\"Code\"].json[\"timestamp\"]}}&sign={{$node[\"Code\"].json[\"sign\"]}}",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"bodyParameters": {
"parameters": [
{
"name": "msgtype",
"value": "markdown"
},
{
"name": "markdown",
"value": "={ title: \"# 【每日简报】\", text: '{{ $json.content }}' }"
}
]
},
"options": {
}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [900, -80],
"id": "5dc96e02-5475-4d78-a086-bd7c196123f4",
"name": "HTTP Request",
"alwaysOutputData": true,
"notesInFlow": false
},
{
"parameters": {
},
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [1280, -80],
"id": "739511da-b2e4-4d9d-a9f4-547b75043e69",
"name": "No Operation, do nothing"
},
{
"parameters": {
"jsCode": "const crypto = require('crypto');\n\n// 设置签名参数\nconst secret = \"your_secret\";\nconst timestamp = Math.floor(Date.now());\nconst stringToSign = `${timestamp}\\n${secret}`;\n\n// 使用 Crypto 模块生成 HMAC-SHA256 签名\nconst hmac = crypto\n .createHmac('sha256', secret) // 指定算法和密钥\n .update(stringToSign) // 更新待签名字符串\n .digest('base64'); // 生成 Base64 格式的签名\n\n// 返回签名和时间戳\nreturn {\n timestamp,\n sign: hmac,\n content: $node[\"RSS\"].json['contentSnippet'].replace('#', '# ').replace(\"\\n来源: 新京报、澎湃新闻、人民网、腾讯新闻、新华网、环球时报等\", \"\").replaceAll(\"\\n\",'\\n- ')\n };\n"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [580, -60],
"id": "aa6431fc-400e-4ab1-820e-ee4d80b3d34f",
"name": "Code"
},
{
"parameters": {
"pollTimes": {
"item": [
{
"mode": "everyHour"
}
]
},
"feedUrl": "https://app.yhy.gd.cn/telegram/channel/NEWSPJAPK"
},
"type": "n8n-nodes-base.rssFeedReadTrigger",
"typeVersion": 1,
"position": [-460, -120],
"id": "454229a4-0086-4bf4-8a21-998b82fe9852",
"name": "RSS"
}
],
"pinData": {
},
"connections": {
"Loop Over Items": {
"main": [
[
{
"node": "Code",
"type": "main",
"index": 0
}
],
[
{
"node": "Replace Me",
"type": "main",
"index": 0
}
]
]
},
"Replace Me": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"HTTP Request": {
"main": [
[
{
"node": "No Operation, do nothing",
"type": "main",
"index": 0
}
]
]
},
"Code": {
"main": [
[
{
"node": "HTTP Request",
"type": "main",
"index": 0
}
]
]
},
"RSS": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
}
},
"active": true,
"settings": {
"executionOrder": "v1"
},
"versionId": "3533e5bd-8496-4a14-9e25-300fdc162a61",
"meta": {
"instanceId": "48efb148eff44c184afe18684e2d9e93e7684821114eb499baa82c0718451784"
},
"id": "33y8Nrozo1iedT96",
"tags": [
{
"createdAt": "2025-01-08T14:02:15.911Z",
"updatedAt": "2025-01-08T14:02:15.911Z",
"id": "QbMJV9YHxcdqY8q3",
"name": "dingding"
}
]
}
本文首发于笨鸟先飞的博客,转载请注明出处。
